Diffusion models are latent variable models of the form , where are latents of the same dimensionality as the data . represents true data observations such as natural images, represents pure Gaussian noise, and is an intermediate noisy version of . The joint distribution is called the reverse process, and it is defined as a Markov chain (shown in Fig.1) with learned Gaussian transitions starting at :
where .
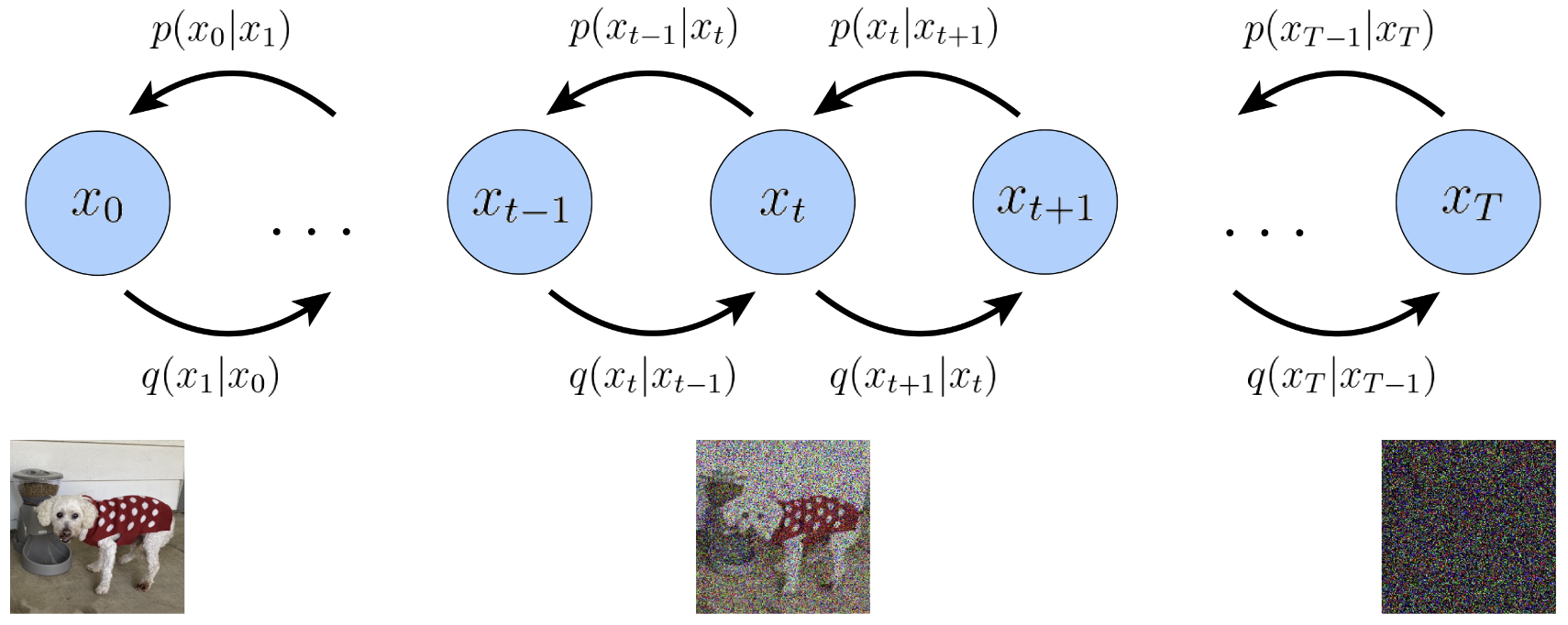
What distinguishes diffusion models from other types of latent variable models is that the approximate posterior , called the forward process or diffusion process, is fixed to a Markov chain that gradually adds Gaussian noise to the data according to a variance schedule.
Diffusion Process
For a diffusion process from to ,
where and . Generally, always close to and can be considered as noise degree and is the Gaussian noise to diffuse .
Thus we can get:
Since , so , so as others. Thus .
When ,
So , where , .
Reverse Process
We are trying to minimize the distance between original image and de-noised image , i.e.:
\begin{aligned} \mathcal{L} &= || x_{t-1} - \theta(x_t) ||^2 \\\\ &= || \frac{1}{\alpha_t}(x_t - \beta_t \epsilon_t) - \theta(x_t) ||^2 \\\\ &= || \frac{1}{\alpha_t}(x_t - \beta_t \epsilon_t) - \frac{1}{\alpha}(x_t - \beta_t \epsilon_{\theta}(x_t, t)) ||^2 \\\\ &= \frac{\beta_t^2}{\alpha_t^2} || \epsilon_t - \epsilon_{\theta}(x_t, t) || ^2 \\\\ &\approx || \epsilon_t - \epsilon_{\theta}(\alpha_t x_{t-1} + \beta_t \epsilon_t, t) || ^2 \\\\ &= || \epsilon_t - \epsilon_{\theta}(\alpha_t (\bar_{\alpha}_{t-1} x_0 + \bar{\beta}_{t-1}\bar{\epsilon}_{t-1}) + \beta_t \epsilon_t, t) || ^2 \\\\ &= || \epsilon_t - \epsilon_{\theta}(\bar{\alpha}_t x_0 + \alpha_t \bar{\beta}_{t-1}\bar{\epsilon}_{t-1} + \beta_t\epsilon_t, t) || ^2 \end{aligned}We resample without because and are not independent.
Currently we have four variable need to sample: , , and . We can use a trick to reduce the variance of training by combining and :