$\pi_{0.5}$: A Vision-Language-Action Model with Open-World Generalization
The design of $\pi_{0.5}$ follows a simple hierarchical architecture: they first pre-train the model on the heterogeneous mixture of training tasks, and then fine-tune it specifically for mobile manipulation with both low-level action examples and high-level "semantic" actions, which correspond to predicting subtask labels such as "pick up the cutting board" or "rearrange the pillow".
The policy distribution is:
\[ \pi_{\theta}(a_{t:t+H}, \hat{l} | o_t, l) = \pi_{\theta}(a_{t:t+H} | o_t, \hat{l}) \pi_{\theta}(\hat{l} | o_t, l) \]
where the action distribution only conditioned on $\hat{l}$, not $l$. $o_t$ contains the images from all of the cameras and the robot's configuration (joint angles, gripper pose, torso lift pose, and base velocity). $l$ is the overall task prompt, and $\hat{l}$ is the model's (tokenized) textual output, which could be either a predicted high-level subtask or the answer to a vision-language prompt in web data.
A full prefix mask is used on images, prompt tokens, and proprioceptive state: FAST action tokens attend to this prefix and auto-regressively on previous action tokens. Embeddings from the action expert embeddings attend to the prefix and to one another, but do not attend to FAST action tokens to avoid information leakage between the two representations of actions. In effect, information flows unidirectionally from the VLM to the action expert; no VLM embedding attends to the action expert.
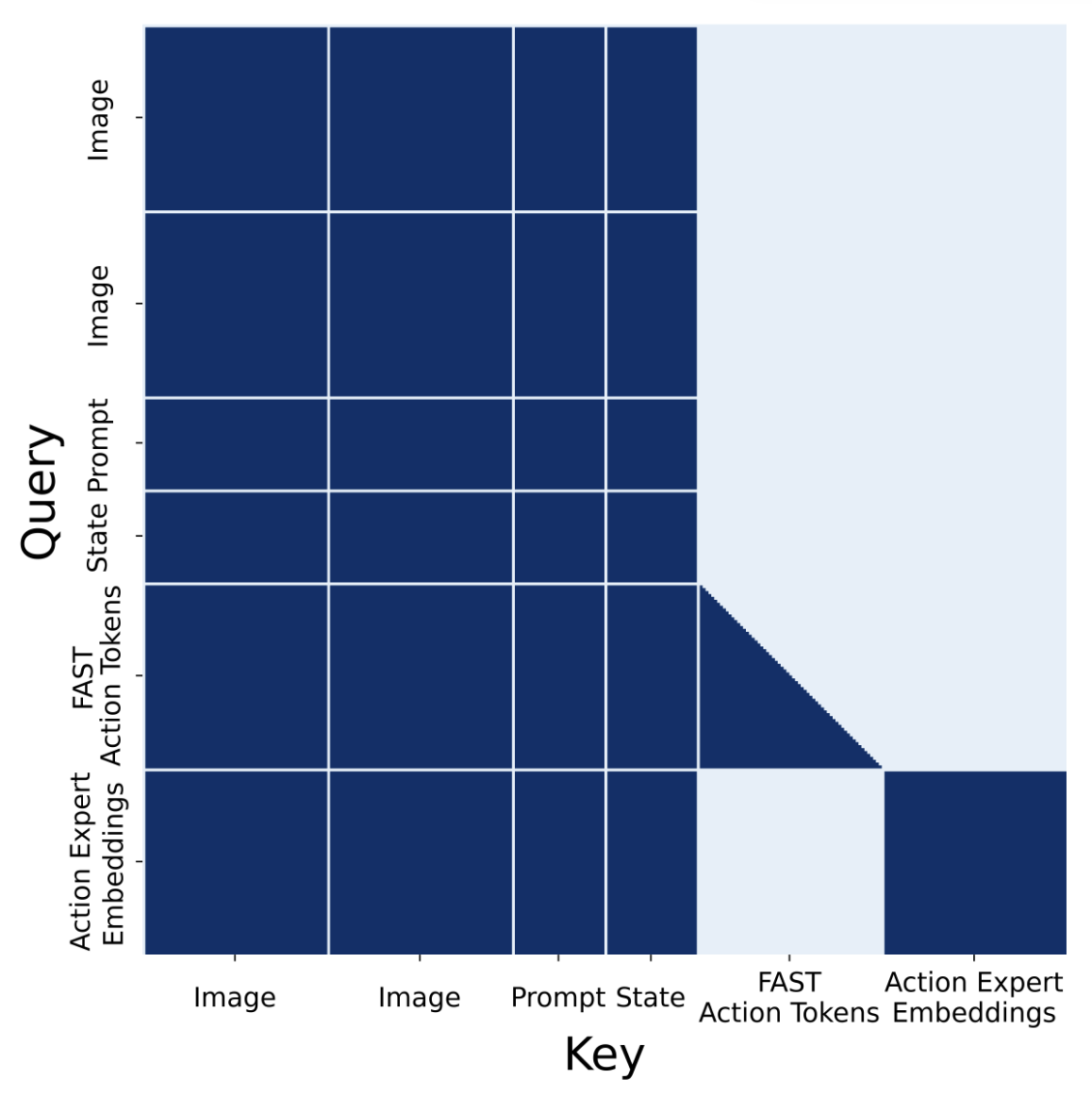
Advantages
- Bidirectional: state and vision-language mutually contextualize each other.
Disadvantages
- Discretization loss: continuous proprioceptive state → discrete tokens loses precision
- Semantic mismatch: treating joint angles as "words" is conceptually awkward.
- Computational: longer sequence = quadratic attention cost.